We can't find the internet
Attempting to reconnect
Something went wrong!
Hang in there while we get back on track
Understanding and Implementing Retrieval Augmented Generation (RAG)
628
clicks

Source: dockyard.com
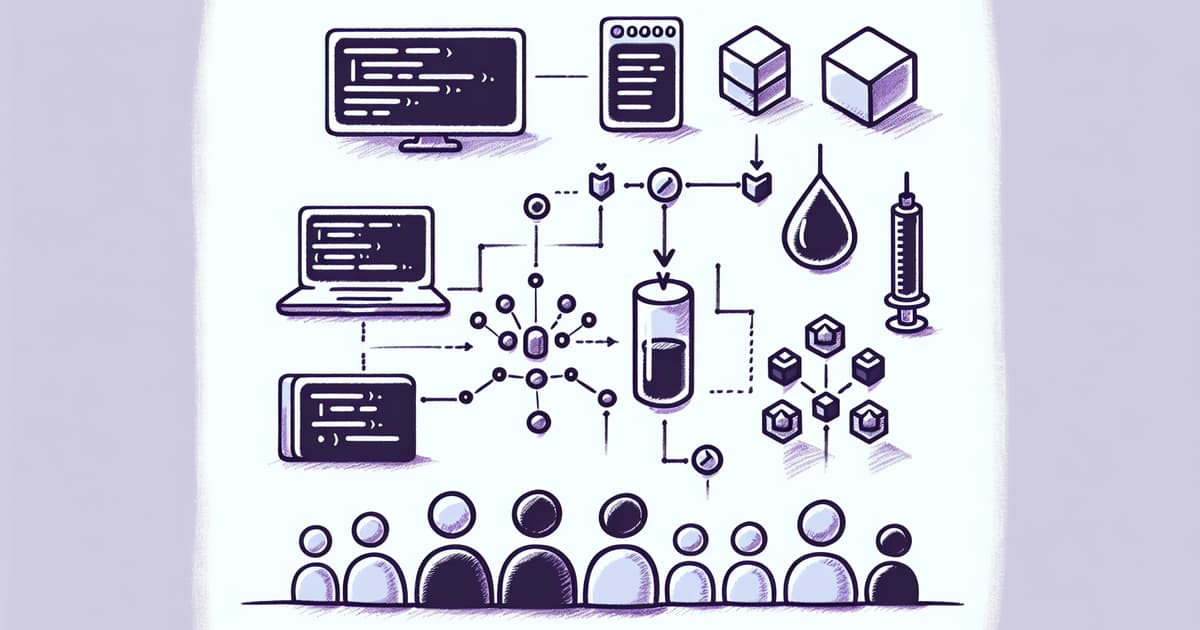
Sean Moriarity provides a comprehensive guide on Retrieval Augmented Generation (RAG), a technique that enhances the capabilities of large language models (LLMs) by integrating information retrieval. The article explains that RAG retrieves relevant context from a corpus, injects it into the prompt for the LLM, and has the LLM generate output based on this augmented prompt. Moriarity discusses two main approaches to enhancing LLMs – fine-tuning and in-context learning, with a focus on the latter due to its efficiency and recent improvements in LLM capabilities. The guide includes detailed steps for setting up a basic RAG pipeline in Elixir, utilizing embedding models, vector databases, and different LLM services. The article also explores advanced techniques to improve RAG pipelines such as query expansion, re-ranking, function calling, document averaging, and generating citations. Evaluations and iterative improvements are emphasized as critical for tuning the performance of RAG solutions.
Related posts

© HashMerge 2026